Cell subsampling using TopACeDo#
%load_ext autotime
import scarf
scarf.__version__
'0.31.4'
time: 827 ms (started: 2025-04-15 15:28:05 +00:00)
1) Installing dependencies#
We need to install the TopACeDo algorithm to perform subsampling:
!pip install -U topacedo
Requirement already satisfied: topacedo in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (0.2.10)
Requirement already satisfied: numpy in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from topacedo) (1.26.4)
Requirement already satisfied: pandas in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from topacedo) (2.2.3)
Requirement already satisfied: scipy in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from topacedo) (1.13.1)
Requirement already satisfied: tqdm in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from topacedo) (4.67.1)
Requirement already satisfied: numba in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from topacedo) (0.61.2)
Requirement already satisfied: networkx in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from topacedo) (3.4.2)
Requirement already satisfied: pcst-fast in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from topacedo) (1.0.10)
Requirement already satisfied: llvmlite<0.45,>=0.44.0dev0 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from numba->topacedo) (0.44.0)
Requirement already satisfied: python-dateutil>=2.8.2 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from pandas->topacedo) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from pandas->topacedo) (2025.2)
Requirement already satisfied: tzdata>=2022.7 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from pandas->topacedo) (2025.2)
Requirement already satisfied: pybind11>=2.1.0 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from pcst-fast->topacedo) (2.13.6)
Requirement already satisfied: six>=1.5 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from python-dateutil>=2.8.2->pandas->topacedo) (1.17.0)
time: 1.04 s (started: 2025-04-15 15:28:05 +00:00)
2) Fetching pre-processed data#
# Loading preanalyzed dataset that was processed in the `basic_tutorial` vignette
scarf.fetch_dataset(
dataset_name='tenx_5K_pbmc_rnaseq',
as_zarr=True,
save_path='scarf_datasets'
)
time: 23 s (started: 2025-04-15 15:28:06 +00:00)
ds = scarf.DataStore('scarf_datasets/tenx_5K_pbmc_rnaseq/data.zarr')
ds.plot_layout(
layout_key='RNA_UMAP',
color_by='RNA_cluster'
)
/home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages/scarf/plots.py:597: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
centers = df[[x, y, vc]].groupby(vc).median().T
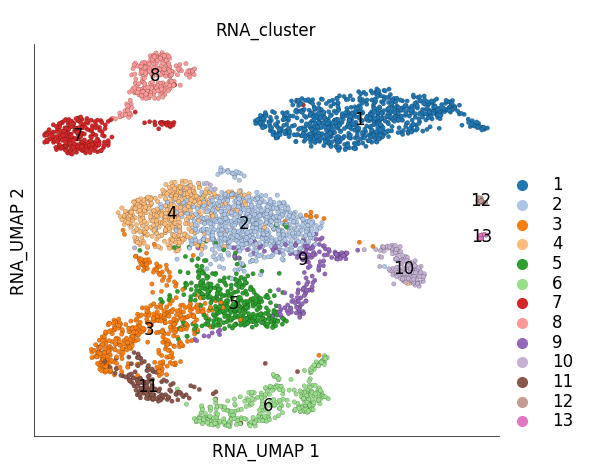
time: 976 ms (started: 2025-04-15 15:28:29 +00:00)
3) Run TopACeDo downsampler#
UMAP, clustering and marker identification together allow a good understanding of cellular diversity. However, one can still choose from a plethora of other analysis on the data. For example, identification of cell differentiation trajectories. One of the major challenges to run these analysis could be the size of the data. Scarf performs a topology conserving downsampling of the data based on the cell neighbourhood graph. This downsampling aims to maximize the heterogeneity while sampling cells from the data.
Here we run the TopACeDo downsampling algorithm that leverages Scarf’s KNN graph to perform a manifold preserving subsampling of cells. The subsampler can be invoked directly from Scarf’s DataStore object.
ds.run_topacedo_sampler(
cluster_key='RNA_cluster',
max_sampling_rate=0.1
)
Constructing graph from dendrogram: 0%| | 0/3939 [00:00<?, ?it/s]
Constructing graph from dendrogram: 100%|██████████| 3939/3939 [00:00<00:00, 71024.19it/s]
INFO: 384 cells (9.75%) sub-sampled. Subsample to Seed (165 cells) ratio: 2.327
time: 1.06 s (started: 2025-04-15 15:28:30 +00:00)
As a result of subsampling the subsampled cells are marked True under the cell metadata column RNA_sketched. We can visualize these cells using plot_layout
ds.plot_layout(
layout_key='RNA_UMAP',
color_by='RNA_cluster',
subselection_key='RNA_sketched'
)
/home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages/scarf/plots.py:597: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
centers = df[[x, y, vc]].groupby(vc).median().T
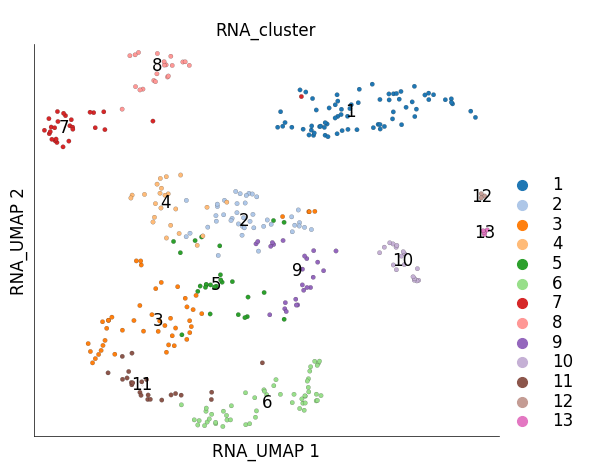
time: 260 ms (started: 2025-04-15 15:28:31 +00:00)
It may also be interesting to visualize the cells that were marked as seed cells used when PCST was run. These cells are marked under the column RNA_sketch_seeds.
ds.plot_layout(
layout_key='RNA_UMAP',
color_by='RNA_cluster',
subselection_key='RNA_sketch_seeds'
)
/home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages/scarf/plots.py:597: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
centers = df[[x, y, vc]].groupby(vc).median().T

time: 255 ms (started: 2025-04-15 15:28:32 +00:00)
4) Intermediate parameters of downsampling#
To identify the seed cells, the subsampling algorithm calculates cell densities based on neighbourhood degrees. Regions of higher cell density get a sampling penalty. The neighbourhood degree of individual cells are stored under the column RNA_cell_density.
ds.plot_layout(
layout_key='RNA_UMAP',
color_by='RNA_cell_density'
)
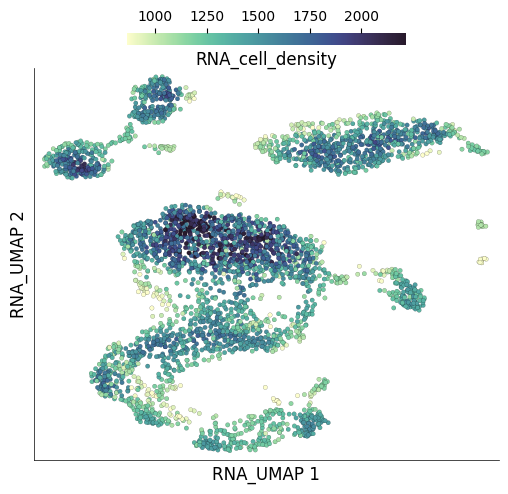
time: 245 ms (started: 2025-04-15 15:28:32 +00:00)
The dowsampling algorithm also identifies regions of the graph where cells form tightly connected groups by calculating mean shared nearest neighbours of each cell’s nieghbours. The tightly connected regions get a sampling award. These values can be accessed from under the cell metadata column RNA_snn_value.
ds.plot_layout(
layout_key='RNA_UMAP',
color_by='RNA_snn_value'
)
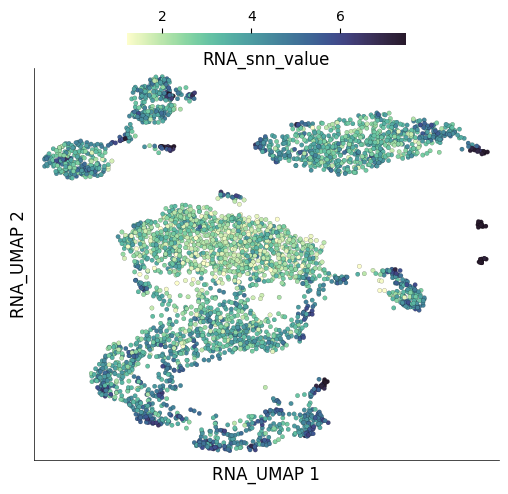
time: 246 ms (started: 2025-04-15 15:28:32 +00:00)
5) Exporting downsampled data#
TopACeDo only marks the cells the representative that for downsampling. To create a new subsampled datasets, SubsetZarr writer class must be used. This will create a new Zarr file containing only the subset of cells.
writer = scarf.SubsetZarr(
zarr_loc='scarf_datasets/tenx_5K_pbmc_rnaseq/subset.zarr',
assays=[ds.RNA],
cell_key='RNA_sketched',
reset_cell_filter=False
)
writer.dump()
time: 1.18 s (started: 2025-04-15 15:28:32 +00:00)
The downsampled dataset can be loaded as a new DataStore
ds2 = scarf.DataStore('scarf_datasets/tenx_5K_pbmc_rnaseq/subset.zarr')
time: 720 ms (started: 2025-04-15 15:28:34 +00:00)
ds2
DataStore has 384 (384) cells with 1 assays: RNA
Cell metadata:
'I', 'ids', 'names', 'RNA_UMAP1', 'RNA_UMAP2',
'RNA_cell_density', 'RNA_cluster', 'RNA_leiden_cluster', 'RNA_nCounts', 'RNA_nFeatures',
'RNA_percentMito', 'RNA_percentRibo', 'RNA_sketch_seeds', 'RNA_sketched', 'RNA_snn_value',
'RNA_tSNE1', 'RNA_tSNE2'
RNA assay has 8773 (33538) features and following metadata:
'I', 'ids', 'names', 'dropOuts', 'nCells',
time: 5.35 ms (started: 2025-04-15 15:28:34 +00:00)
It is expected the downsampled dataset will be small enough to fit in memory. Here the data is exported to anndata format from where it could easily used to perform any downstream analysis from the scverse ecosystem.
!pip install anndata
Collecting anndata
Downloading anndata-0.11.4-py3-none-any.whl.metadata (9.3 kB)
Collecting array-api-compat!=1.5,>1.4 (from anndata)
Downloading array_api_compat-1.11.2-py3-none-any.whl.metadata (1.9 kB)
Requirement already satisfied: h5py>=3.7 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from anndata) (3.13.0)
Collecting natsort (from anndata)
Downloading natsort-8.4.0-py3-none-any.whl.metadata (21 kB)
Requirement already satisfied: numpy>=1.23 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from anndata) (1.26.4)
Requirement already satisfied: packaging>=24.2 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from anndata) (24.2)
Requirement already satisfied: pandas!=2.1.0rc0,!=2.1.2,>=1.4 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from anndata) (2.2.3)
Requirement already satisfied: scipy>1.8 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from anndata) (1.13.1)
Requirement already satisfied: python-dateutil>=2.8.2 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from pandas!=2.1.0rc0,!=2.1.2,>=1.4->anndata) (2.9.0.post0)
Requirement already satisfied: pytz>=2020.1 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from pandas!=2.1.0rc0,!=2.1.2,>=1.4->anndata) (2025.2)
Requirement already satisfied: tzdata>=2022.7 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from pandas!=2.1.0rc0,!=2.1.2,>=1.4->anndata) (2025.2)
Requirement already satisfied: six>=1.5 in /home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages (from python-dateutil>=2.8.2->pandas!=2.1.0rc0,!=2.1.2,>=1.4->anndata) (1.17.0)
Downloading anndata-0.11.4-py3-none-any.whl (144 kB)
Downloading array_api_compat-1.11.2-py3-none-any.whl (53 kB)
Downloading natsort-8.4.0-py3-none-any.whl (38 kB)
Installing collected packages: natsort, array-api-compat, anndata
Successfully installed anndata-0.11.4 array-api-compat-1.11.2 natsort-8.4.0
time: 1.25 s (started: 2025-04-15 15:28:34 +00:00)
adata = ds2.to_anndata()
time: 312 ms (started: 2025-04-15 15:28:36 +00:00)
adata
AnnData object with n_obs × n_vars = 384 × 33538
obs: 'I', 'names', 'RNA_UMAP1', 'RNA_UMAP2', 'RNA_cell_density', 'RNA_cluster', 'RNA_leiden_cluster', 'RNA_nCounts', 'RNA_nFeatures', 'RNA_percentMito', 'RNA_percentRibo', 'RNA_sketch_seeds', 'RNA_sketched', 'RNA_snn_value', 'RNA_tSNE1', 'RNA_tSNE2'
var: 'I', 'names', 'dropOuts', 'nCells'
time: 1.72 ms (started: 2025-04-15 15:28:36 +00:00)
That is all for this vignette.