Scarf’s basic workflow for scRNA-Seq#
This workflow is meant to familiarize users with the Scarf API and how data is internally handled in Scarf. Please checkout the quick start guide if you are interested in the minimal steps required to run the analysis.
%load_ext autotime
import scarf
scarf.__version__
'0.31.4'
time: 1.28 s (started: 2025-04-15 15:26:30 +00:00)
Download the count matrix from 10x’s website using the fetch_dataset function. This is a convenience function that stores URLs of datasets that can be downloaded. The save_path parameter allows the data to be saved to a location of choice.
scarf.fetch_dataset(
'tenx_5K_pbmc_rnaseq',
save_path='scarf_datasets'
)
time: 19.5 s (started: 2025-04-15 15:26:31 +00:00)
1) Format conversion#
The first step of the analysis workflow is to convert the file into the Zarr format that is supported by Scarf. We read in the data using CrH5Reader (stands for cellranger H5 reader). The reader object allows quick investigation of the file before the format is converted.
reader = scarf.CrH5Reader('scarf_datasets/tenx_5K_pbmc_rnaseq/data.h5')
time: 19.3 ms (started: 2025-04-15 15:26:51 +00:00)
We can quickly check the number of cells and features (genes as well as ADT features in this case) present in the file.
reader.nCells, reader.nFeatures
(5025, 33538)
time: 1.48 ms (started: 2025-04-15 15:26:51 +00:00)
Next we convert the data to the Zarr format that will later on be used by Scarf. For this we use Scarf’s CrToZarr class. This class will first quickly ascertain the type of data to be written and then create a Zarr format file for the data to be written into. CrToZarr takes two mandatory arguments. The first is the cellranger reader, and the other is the name of the output file.
writer = scarf.CrToZarr(
reader,
zarr_loc='scarf_datasets/tenx_5K_pbmc_rnaseq/data.zarr',
chunk_size=(2000, 1000)
)
writer.dump(batch_size=1000)
time: 2.53 s (started: 2025-04-15 15:26:51 +00:00)
The next step is to create a Scarf DataStore object. This object will be the primary way to interact with the data and all its constituent assays. When a Zarr file is loaded, Scarf checks if some per-cell statistics have been calculated. If not, then nFeatures (number of features per cell) and nCounts (total sum of feature counts per cell) are calculated. Scarf will also attempt to calculate the percent of mitochondrial and ribosomal content per cell. When we create a DataStore instance, we can decide to filter out low abundance genes with parameter min_features_per_cell. For example the value of 10 for min_features_per_cell below means that those genes that are present in less than 10 cells will be filtered out.
ds = scarf.DataStore(
'scarf_datasets/tenx_5K_pbmc_rnaseq/data.zarr',
nthreads=4,
min_features_per_cell=10
)
WARNING: Minimum cell count (502) is lower than size factor multiplier (1000)
time: 2.65 s (started: 2025-04-15 15:26:53 +00:00)
2) Cell filtering#
We can visualize the per-cell statistics in violin plots before we start filtering cells out.
ds.plot_cells_dists()
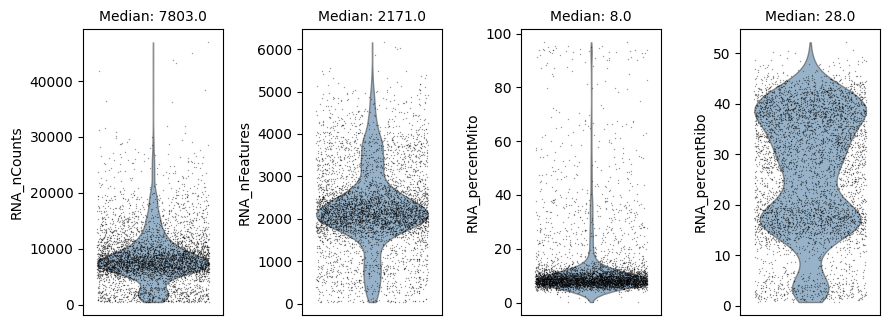
time: 1.43 s (started: 2025-04-15 15:26:56 +00:00)
We can filter cells based on these cell attributes by providing upper and lower threshold values.
ds.filter_cells(
attrs=['RNA_nCounts', 'RNA_nFeatures', 'RNA_percentMito'],
highs=[15000, 4000, 15],
lows=[1000, 500, 0]
)
INFO: 597 cells flagged for filtering out using attribute RNA_nCounts
INFO: 461 cells flagged for filtering out using attribute RNA_nFeatures
INFO: 612 cells flagged for filtering out using attribute RNA_percentMito
time: 8.7 ms (started: 2025-04-15 15:26:58 +00:00)
All functions in the DataStore class, take a parameter called cell_key. The default value of this parameter is always I which means that the I column is always automatically looked up when deciding which cells to use. The added benefit of this approach is that a user can always switch the context of which cells by creating a new boolean column and providing the name of that column to cell_key. Read more about this in the ‘Data organization’ vignette.
Now we visualize the attributes again after filtering the values.
Note: the ‘I’ value given as the cell_key attribute signifies the column of the table that is set to False for cells that were filtered out or True for cells that are kept.
ds.plot_cells_dists(cell_key='I', color='coral')
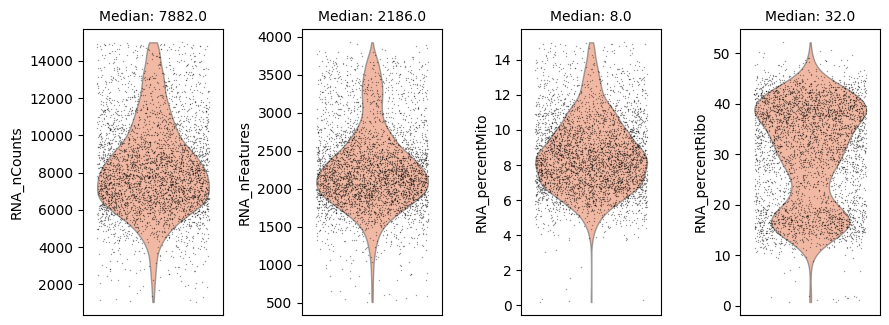
time: 579 ms (started: 2025-04-15 15:26:58 +00:00)
The data stored under the ‘cellData’ level can easily be accessed using the cells attribute of the DataStore object.
ds.cells.head()
| I | ids | names | RNA_nCounts | RNA_nFeatures | RNA_percentMito | RNA_percentRibo | |
|---|---|---|---|---|---|---|---|
| 0 | True | AAACCCAAGCGTATGG-1 | AAACCCAAGCGTATGG-1 | 13537.0 | 3503.0 | 10.844353 | 16.783630 |
| 1 | True | AAACCCAGTCCTACAA-1 | AAACCCAGTCCTACAA-1 | 12668.0 | 3381.0 | 5.975687 | 20.034733 |
| 2 | False | AAACCCATCACCTCAC-1 | AAACCCATCACCTCAC-1 | 962.0 | 346.0 | 53.430353 | 2.494802 |
| 3 | True | AAACGCTAGGGCATGT-1 | AAACGCTAGGGCATGT-1 | 5788.0 | 1799.0 | 10.919143 | 28.783690 |
| 4 | True | AAACGCTGTAGGTACG-1 | AAACGCTGTAGGTACG-1 | 13186.0 | 2887.0 | 7.955407 | 35.750038 |
time: 14.9 ms (started: 2025-04-15 15:26:58 +00:00)
cells attribute. Please refer to the insert, fetch, fetch_all, drop and update_key methods.
One can now print the DataStore instance to get an overview of the data. The number of cells and genes post filtering are also indicated. The numbers in brackets indicate the total number of cells (5025 in this case) and total number of features in the RNA assay (33538 in this case).
ds
DataStore has 3940 (5025) cells with 1 assays: RNA
Cell metadata:
'I', 'ids', 'names', 'RNA_nCounts', 'RNA_nFeatures',
'RNA_percentMito', 'RNA_percentRibo'
RNA assay has 14283 (33538) features and following metadata:
'I', 'ids', 'names', 'dropOuts', 'nCells',
time: 5.07 ms (started: 2025-04-15 15:26:58 +00:00)
3) Feature selection#
Similar to the cell table, Scarf also saves the feature level data that can be accessed as below:
ds.RNA.feats.head()
| I | ids | names | dropOuts | nCells | |
|---|---|---|---|---|---|
| 0 | False | ENSG00000243485 | MIR1302-2HG | 5025 | 0 |
| 1 | False | ENSG00000237613 | FAM138A | 5025 | 0 |
| 2 | False | ENSG00000186092 | OR4F5 | 5025 | 0 |
| 3 | True | ENSG00000238009 | AL627309.1 | 4976 | 49 |
| 4 | False | ENSG00000239945 | AL627309.3 | 5022 | 3 |
time: 13.1 ms (started: 2025-04-15 15:26:58 +00:00)
The feature selection step is performed on the normalized data. The default normalization method for RNAassay-type data is library-size normalization, wherein the count values are divided by the sum of total values for a cell. These values are then multiplied by a scalar factor. The default value of this scalar factor is 1000. However, if the total counts in a cell are less than this value, then on multiplication with this scalar factor the values will be ‘scaled up’ (which is not a desired behaviour). In the filtering step above, we set the low threshold for RNA_nCounts at 1000, and hence it is safe to use 1000 as a scalar factor. The scalar factor can be set by modifying the sf attribute of the assay. Let’s print the default value of sf
ds.RNA.sf
1000
time: 1.3 ms (started: 2025-04-15 15:26:58 +00:00)
Now the next step is to identify the highly variable genes in the dataset (for the RNA assay). This can be done using the mark_hvgs method of the assay. The parameters govern the min/max variance (corrected) and mean expression threshold for calling genes highly variable.
The variance is corrected by first dividing genes into bins based on their mean expression values. Genes with minimum variance is selected from each bin and a Lowess curve is fitted to the mean-variance trend of these genes. mark_hvgs will by default run on the default assay.
A plot is produced, that for each gene shows the corrected variance on the y-axis and the non-zero mean (means from cells where the gene had a non-zero value) on the x-axis. The genes are colored in two gradients which indicate the number of cells where the gene was expressed. The colors are yellow to dark red for HVGs, and blue to green for non-HVGs.
The mark_hvgs function has a parameter cell_key that dictates which cells to use to identify the HVGs. The default value of this parameter is I, which means it will use all the cells that were not filtered out.
ds.mark_hvgs(
min_cells=20,
top_n=500,
min_mean=-3,
max_mean=2,
max_var=6
)
INFO: Calculating summary statistics
INFO: Calculating HVGs
INFO: 498 genes marked as HVGs
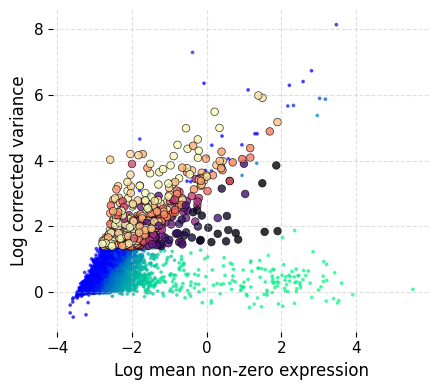
time: 3.45 s (started: 2025-04-15 15:26:58 +00:00)
As a result of running mark_hvgs, the feature table now has an extra column I__hvgs which contains a True value for genes marked HVGs. The naming rule in Scarf dictates that cells used to identify HVGs are prepended to the column name (with a double underscore delimiter). Since we did not provide any cell_key parameter the default value was used, i.e. the filtered cells. This resulted in I becoming the prefix.
ds.RNA.feats.head()
| I | ids | names | I__hvgs | dropOuts | nCells | stats_I_avg | stats_I_c_var__200__0.1 | stats_I_normed_n | stats_I_normed_tot | stats_I_nz_mean | stats_I_sigmas | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | False | ENSG00000243485 | MIR1302-2HG | False | 5025 | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | False | ENSG00000237613 | FAM138A | False | 5025 | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | False | ENSG00000186092 | OR4F5 | False | 5025 | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | True | ENSG00000238009 | AL627309.1 | False | 4976 | 49 | 0.000914 | 1.5279 | 33.0 | 4.593283 | 0.13919 | 0.000196 |
| 4 | False | ENSG00000239945 | AL627309.3 | False | 5022 | 3 | NaN | NaN | NaN | NaN | NaN | NaN |
time: 24.4 ms (started: 2025-04-15 15:27:02 +00:00)
4) Graph creation#
Creating a neighbourhood graph of cells is the most critical step in any Scarf workflow. This step internally involves multiple substeps:
data normalization for selected features
linear dimensionality reduction using PCA
creating an approximate nearest neighbour graph index (using the HNSWlib library)
querying cells against this index to identify nearest neighbours for each cell
edge weight computation using the
compute_membership_strengthsfunction from the UMAP packagefitting MiniBatch Kmeans (The kmeans centers are used later, for UMAP initialization)
The make_graph method is responsible for graph construction. Its method takes a mandatory parameter: feat_key. This should be a column in the feature metadata table that indicates which genes to use to create the graph. Since we have already identified the hvgs in the step above, we use those genes. Note that we do not need to write I__hvgs but just hvgs as the value of the parameter. We also supply values for two very important parameters here: k (number of nearest neighbours to be queried for each cell) and dims (number of PCA dimensions to use for graph construction). n_centroids parameter controls number of clusters to create for the data using the Kmeans algorithm. We perform a more accurate clustering of data in the later steps.
ds.make_graph(
feat_key='hvgs',
k=11,
dims=15,
n_centroids=100
)
INFO: ANN recall: 99.92%
time: 18 s (started: 2025-04-15 15:27:02 +00:00)
5) Low dimensional embedding and clustering#
Next we run UMAP on the graph calculated above. Here we will not provide which cell key or feature key to be used, because we want the UMAP to run on all the cells that were not filtered out and with the feature key used to calculate the latest graph. We can provide the parameter values for the UMAP algorithm here.
ds.run_umap(
n_epochs=250,
spread=5,
min_dist=1,
parallel=True
)
completed 0 / 250 epochs
completed 25 / 250 epochs
completed 50 / 250 epochs
completed 75 / 250 epochs
completed 100 / 250 epochs
completed 125 / 250 epochs
completed 150 / 250 epochs
completed 175 / 250 epochs
completed 200 / 250 epochs
completed 225 / 250 epochs
time: 3.36 s (started: 2025-04-15 15:27:20 +00:00)
The UMAP results are saved in the cell metadata table as seen below in columns: RNA_UMAP1 and RNA_UMAP2
ds.cells.head()
| I | ids | names | RNA_UMAP1 | RNA_UMAP2 | RNA_nCounts | RNA_nFeatures | RNA_percentMito | RNA_percentRibo | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | True | AAACCCAAGCGTATGG-1 | AAACCCAAGCGTATGG-1 | 6.144978 | 31.025629 | 13537.0 | 3503.0 | 10.844353 | 16.783630 |
| 1 | True | AAACCCAGTCCTACAA-1 | AAACCCAGTCCTACAA-1 | 18.561081 | 18.732515 | 12668.0 | 3381.0 | 5.975687 | 20.034733 |
| 2 | False | AAACCCATCACCTCAC-1 | AAACCCATCACCTCAC-1 | NaN | NaN | 962.0 | 346.0 | 53.430353 | 2.494802 |
| 3 | True | AAACGCTAGGGCATGT-1 | AAACGCTAGGGCATGT-1 | -23.661673 | 24.943319 | 5788.0 | 1799.0 | 10.919143 | 28.783690 |
| 4 | True | AAACGCTGTAGGTACG-1 | AAACGCTGTAGGTACG-1 | -10.774677 | -4.783125 | 13186.0 | 2887.0 | 7.955407 | 35.750038 |
time: 16 ms (started: 2025-04-15 15:27:23 +00:00)
plot_layout is a versatile method to create a scatter plot using Scarf. Here we can plot the UMAP coordinates of all the non-filtered out cells.
ds.plot_layout(layout_key='RNA_UMAP')

time: 137 ms (started: 2025-04-15 15:27:23 +00:00)
plot_layout can be used to easily visualize data from any column of the cell metadata table. Next, we visualize the number of genes expressed in each cell.
ds.plot_layout(
layout_key='RNA_UMAP',
color_by='RNA_nCounts',
cmap='coolwarm'
)

time: 275 ms (started: 2025-04-15 15:27:23 +00:00)
There has been a lot of discussion over the choice of non-linear dimensionality reduction for single-cell data. tSNE was initially considered an excellent solution, but has gradually lost out to UMAP because the magnitude of relations between the clusters cannot easily be discerned in a tSNE plot. Scarf contains an implementation of tSNE that runs directly on the graph structure of cells. So, essentially the same data that was used to create the UMAP and clustering is used.
ds.run_tsne(
alpha=10,
box_h=1,
early_iter=250,
max_iter=500,
parallel=True
)
ERROR: SG-tSNE failed, possibly due to missing libraries or file permissions. SG-tSNE currently fails on readthedocs
time: 96.2 ms (started: 2025-04-15 15:27:24 +00:00)
sgtsne: error while loading shared libraries: libmetis.so.5: cannot open shared object file: No such file or directory
# Here we run plot_layout under exception catching because if you are not on Linux then the `run_tnse` would have failed.
try:
ds.plot_layout(layout_key='RNA_tSNE')
except KeyError:
print ("'RNA_tSNE1' not found in MetaData")
'RNA_tSNE1' not found in MetaData
time: 1.25 ms (started: 2025-04-15 15:27:24 +00:00)
6) Cell clustering#
Identifying clusters of cells is one of the central tenets of single cell approaches. Scarf includes two graph clustering methods and any (or even both) can be used on the dataset. The methods start with the same graph as the UMAP algorithm above to minimize the disparity between the UMAP and clustering results. The two clustering methods are:
Paris: This is the default clustering algorithm.
Leiden: Leiden is a widely used graph clustering algorithm in single-cell genomics.
Paris is the default algorithm in Scarf due to its ability to highlight cluster relationships. Paris is a hierarchical graph clustering algorithm that is based on node pair sampling. Paris creates a dendrogram of cells which can then be cut to obtain desired number of clusters. The advantage of using Paris, especially in the larger datasets, is that once the dendrogram has been created one can change the desired number of clusters with minimal computation overhead.
# We start with Leiden clustering
ds.run_leiden_clustering(resolution=0.5)
time: 325 ms (started: 2025-04-15 15:27:24 +00:00)
We can visualize the results using the plot_layout method again. Here we plot both UMAP and colour cells based on their cluster identity, as obtained using Leiden clustering.
ds.plot_layout(
layout_key='RNA_UMAP',
color_by='RNA_leiden_cluster'
)
/home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages/scarf/plots.py:597: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
centers = df[[x, y, vc]].groupby(vc).median().T

time: 265 ms (started: 2025-04-15 15:27:24 +00:00)
The results of the clustering algorithm are saved in the cell metadata table. In this case, they have been saved under the column name RNA_leiden_cluster.
ds.cells.head()
| I | ids | names | RNA_UMAP1 | RNA_UMAP2 | RNA_leiden_cluster | RNA_nCounts | RNA_nFeatures | RNA_percentMito | RNA_percentRibo | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | True | AAACCCAAGCGTATGG-1 | AAACCCAAGCGTATGG-1 | 6.144978 | 31.025629 | 2 | 13537.0 | 3503.0 | 10.844353 | 16.783630 |
| 1 | True | AAACCCAGTCCTACAA-1 | AAACCCAGTCCTACAA-1 | 18.561081 | 18.732515 | 2 | 12668.0 | 3381.0 | 5.975687 | 20.034733 |
| 2 | False | AAACCCATCACCTCAC-1 | AAACCCATCACCTCAC-1 | NaN | NaN | -1 | 962.0 | 346.0 | 53.430353 | 2.494802 |
| 3 | True | AAACGCTAGGGCATGT-1 | AAACGCTAGGGCATGT-1 | -23.661673 | 24.943319 | 7 | 5788.0 | 1799.0 | 10.919143 | 28.783690 |
| 4 | True | AAACGCTGTAGGTACG-1 | AAACGCTGTAGGTACG-1 | -10.774677 | -4.783125 | 1 | 13186.0 | 2887.0 | 7.955407 | 35.750038 |
time: 17.6 ms (started: 2025-04-15 15:27:24 +00:00)
We can export the Leiden cluster information into a pandas dataframe. Setting key to I makes sure that we do not include the data for cells that were filtered out.
leiden_clusters = ds.cells.to_pandas_dataframe(
columns=['RNA_leiden_cluster'],
key='I'
)
leiden_clusters.head()
| RNA_leiden_cluster | |
|---|---|
| 0 | 2 |
| 1 | 2 |
| 3 | 7 |
| 4 | 1 |
| 6 | 5 |
time: 5.53 ms (started: 2025-04-15 15:27:24 +00:00)
Now we run Paris clustering algorithm using run_clustering method. Paris clustering requires only one parameter: n_clusters, which determines the number of clusters to create. Here we set the number of clusters same as that were obtained using Leiden clustering.leiden_clusters.nunique()
ds.run_clustering(n_clusters=leiden_clusters.nunique()[0])
/tmp/ipykernel_1134/1807300542.py:1: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
ds.run_clustering(n_clusters=leiden_clusters.nunique()[0])
time: 245 ms (started: 2025-04-15 15:27:24 +00:00)
Visualizing Paris clusters
ds.plot_layout(
layout_key='RNA_UMAP',
color_by='RNA_cluster'
)
/home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages/scarf/plots.py:597: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
centers = df[[x, y, vc]].groupby(vc).median().T

time: 276 ms (started: 2025-04-15 15:27:24 +00:00)
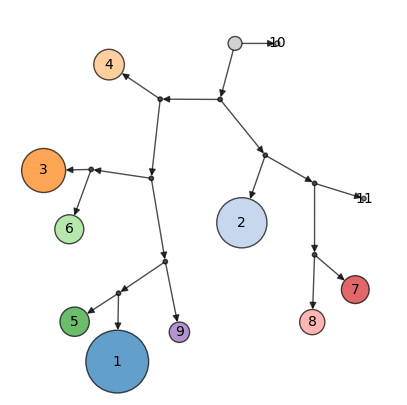
Discerning similarity between clusters can be difficult from visual inspection alone, especially for tSNE plots. plot_cluster_tree function plots the relationship between clusters as a binary tree. This tree is simply a condensation of the dendrogram obtained using Paris clustering.
ds.plot_cluster_tree(cluster_key='RNA_cluster', width=1)
time: 604 ms (started: 2025-04-15 15:27:25 +00:00)
The tree is free form (i.e the position of clusters doesn’t convey any meaning) but allows inspection of cluster similarity based on branching pattern. The sizes of clusters indicate the number of cells present in each cluster. The tree starts from the root node (black dot with no incoming edges).
7) Marker gene identification#
Now we can identify the genes that are differentially expressed between the clusters using the run_marker_search method. The method to identify the differentially expressed genes in Scarf is optimized to obtain quick results. We have not compared the sensitivity of our method to other differential expression-detecting methods. We expect specialized methods to be more sensitive and accurate to varying degrees. Our method is designed to quickly obtain key marker genes for populations from a large dataset. For each gene individually, following steps are carried out:
Expression values are converted to ranks (dense format) across cells.
A mean of ranks is calculated for each group of cells.
The mean value for each group is divided by the sum of mean values to obtain the ‘specificity score’.
The gene is saved as a marker gene if it’s specificity score is higher than a given threshold.
This method does not perform any statistical test of significance and uses ‘specificity score’ as a measure of importance of each gene for a cluster.
ds.run_marker_search(
group_key='RNA_cluster',
gene_batch_size=100
)
time: 7.66 s (started: 2025-04-15 15:27:25 +00:00)
Using the plot_marker_heatmap method, we can also plot a heatmap with the top marker genes from each cluster. The method will calculate the mean expression value for each gene from each cluster.
ds.plot_marker_heatmap(
group_key='RNA_cluster',
topn=5,
figsize=(5, 9)
)
/home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/latest/lib/python3.11/site-packages/dask/dataframe/__init__.py:42: FutureWarning:
Dask dataframe query planning is disabled because dask-expr is not installed.
You can install it with `pip install dask[dataframe]` or `conda install dask`.
This will raise in a future version.
warnings.warn(msg, FutureWarning)

time: 885 ms (started: 2025-04-15 15:27:33 +00:00)
The markers list for specific clusters can be obtained using get_markers. The numbers on the left index (in bold) are the gene/feature index as present in the feature attribute table (ds.RNA.feats). The table below is sorted (descending) by scores and this means that more specific markers are placed higher on the list.
df = ds.get_markers(
group_key='RNA_cluster',
group_id='1',
min_score=-1,
min_frac_exp=-1
)
df
| group_id | feature_name | feature_index | score | mean | mean_rest | frac_exp | frac_exp_rest | fold_change | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | TSHZ2 | 29849.0 | 0.37197 | 0.07309 | 0.01475 | 0.34318 | 0.06330 | 4.95367 |
| 1 | 1 | ADTRP | 10307.0 | 0.37084 | 0.04083 | 0.00643 | 0.24309 | 0.03632 | 6.34574 |
| 2 | 1 | FHIT | 6081.0 | 0.35087 | 0.14478 | 0.02292 | 0.62154 | 0.13179 | 6.31594 |
| 3 | 1 | DPYSL4 | 20078.0 | 0.33472 | 0.01491 | 0.00135 | 0.10963 | 0.00969 | 11.02967 |
| 4 | 1 | CHRM3-AS2 | 3027.0 | 0.33356 | 0.06525 | 0.01350 | 0.38227 | 0.08198 | 4.83368 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 14278 | 1 | GAPT | 8945.0 | 0.00135 | 0.00028 | 0.04960 | 0.00191 | 0.24213 | 0.00571 |
| 14279 | 1 | MARCH1 | 8323.0 | 0.00127 | 0.00077 | 0.09898 | 0.00667 | 0.35247 | 0.00783 |
| 14280 | 1 | ZEB2 | 4554.0 | 0.00120 | 0.00240 | 0.19956 | 0.01907 | 0.49983 | 0.01202 |
| 14281 | 1 | MEF2C | 9200.0 | 0.00090 | 0.00048 | 0.09918 | 0.00381 | 0.33656 | 0.00484 |
| 14282 | 1 | PLEK | 3816.0 | 0.00083 | 0.00147 | 0.18137 | 0.00953 | 0.52785 | 0.00811 |
14283 rows × 9 columns
time: 175 ms (started: 2025-04-15 15:27:34 +00:00)
We can directly visualize the expression values for a gene of interest. It is usually a good idea to visually confirm the gene expression pattern across the cells at least this way.
ds.plot_layout(layout_key='RNA_UMAP', color_by='CD14')

time: 316 ms (started: 2025-04-15 15:27:34 +00:00)
That is all for this vignette.