Estimating cell cycle phases#
In this vignette we will demonstrate how to identify cell cycle phases using single-cell RNA-Seq data
%load_ext autotime
import scarf
scarf.__version__
'0.23.5'
time: 1.67 s (started: 2023-05-24 14:28:11 +00:00)
1) Fetch pre-analyzed data#
Here we use the data from Bastidas-Ponce et al., 2019 Development for E15.5 stage of differentiation of endocrine cells from a pool of endocrine progenitors-precursors.
We have stored this data on Scarf’s online repository for quick access. We processed the data to identify the highly variable genes (top 2000) and create a neighbourhood graph of cells. A UMAP embedding was calculated for the cells.
scarf.fetch_dataset(
dataset_name='bastidas-ponce_4K_pancreas-d15_rnaseq',
save_path='./scarf_datasets',
as_zarr=True,
)
time: 16.8 s (started: 2023-05-24 14:28:13 +00:00)
ds = scarf.DataStore(
f"scarf_datasets/bastidas-ponce_4K_pancreas-d15_rnaseq/data.zarr",
nthreads=4,
default_assay='RNA'
)
time: 51.4 ms (started: 2023-05-24 14:28:30 +00:00)
ds.plot_layout(
layout_key='RNA_UMAP',
color_by='clusters'
)
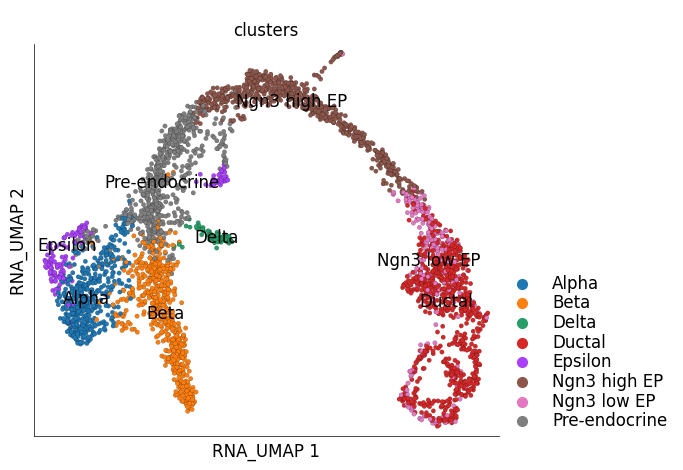
time: 2.07 s (started: 2023-05-24 14:28:30 +00:00)
2) Run cell cycle scoring#
The cell cycle scoring function in Scarf is highly inspired by the equivalent function in Scanpy. The cell cycle phase of each individual cell is identified following steps below:
A list of S and G2M phase is provided to the function (Scarf already has a generic list of genes that works both for human and mouse data)
Average expression of all the genes (separately for S and G2M lists) in across
cell_keycells is calculatedThe log average expression is divided in
n_binsbinsA control set of genes is identified by sampling genes from same expression bins where phase’s genes are present.
The average expression of phase genes (Ep) and control genes (Ec) is calculated per cell.
A phase score is calculated as: Ep-Ec Cell cycle phase is assigned to each cell based on following rule set:
G1 phase: S score < -1 > G2M sore
S phase: S score > G2M score
G2M phase: G2M score > S score
ds.run_cell_cycle_scoring()
WARNING: 1 values were not found in the table column names
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[5], line 1
----> 1 ds.run_cell_cycle_scoring()
File ~/checkouts/readthedocs.org/user_builds/scarf/envs/0.23.5/lib/python3.8/site-packages/scarf/datastore/datastore.py:725, in DataStore.run_cell_cycle_scoring(self, from_assay, cell_key, s_genes, g2m_genes, n_bins, rand_seed, s_score_label, g2m_score_label, phase_label)
722 g2m_genes = list(g2m_phase_genes)
723 control_size = min(len(s_genes), len(g2m_genes))
--> 725 s_score = assay.score_features(
726 s_genes, cell_key, control_size, n_bins, rand_seed
727 )
728 s_score_label = self._col_renamer(from_assay, cell_key, s_score_label)
729 self.cells.insert(s_score_label, s_score, key=cell_key, overwrite=True)
File ~/checkouts/readthedocs.org/user_builds/scarf/envs/0.23.5/lib/python3.8/site-packages/scarf/assay.py:701, in Assay.score_features(self, feature_names, cell_key, ctrl_size, n_bins, rand_seed)
699 identifier = self._load_stats_loc(cell_key)
700 obs_avg = pd.Series(self.feats.fetch_all(f"{identifier}_avg"))
--> 701 control_idx = binned_sampling(
702 obs_avg, list(feature_idx), ctrl_size, n_bins, rand_seed
703 )
704 cell_idx, _ = self._get_cell_feat_idx(cell_key, "I")
705 return _calc_mean(feature_idx) - _calc_mean(control_idx)
File ~/checkouts/readthedocs.org/user_builds/scarf/envs/0.23.5/lib/python3.8/site-packages/scarf/feat_utils.py:80, in binned_sampling(values, feature_list, ctrl_size, n_bins, rand_seed)
77 obs_cut: pd.Series = values.fillna(0).rank(method="min").divide(n_items).astype(int)
79 control_genes = set()
---> 80 for cut in np.unique(obs_cut[feature_list]):
81 # Replaced np.random.shuffle with pandas' sample method
82 r_genes = (
83 obs_cut[obs_cut == cut].sample(n=ctrl_size, random_state=rand_seed).index
84 )
85 control_genes.update(set(r_genes))
File ~/checkouts/readthedocs.org/user_builds/scarf/envs/0.23.5/lib/python3.8/site-packages/pandas/core/series.py:993, in Series.__getitem__(self, key)
992 def __getitem__(self, key):
--> 993 check_dict_or_set_indexers(key)
994 key = com.apply_if_callable(key, self)
996 if key is Ellipsis:
File ~/checkouts/readthedocs.org/user_builds/scarf/envs/0.23.5/lib/python3.8/site-packages/pandas/core/indexing.py:2611, in check_dict_or_set_indexers(key)
2603 """
2604 Check if the indexer is or contains a dict or set, which is no longer allowed.
2605 """
2606 if (
2607 isinstance(key, set)
2608 or isinstance(key, tuple)
2609 and any(isinstance(x, set) for x in key)
2610 ):
-> 2611 raise TypeError(
2612 "Passing a set as an indexer is not supported. Use a list instead."
2613 )
2615 if (
2616 isinstance(key, dict)
2617 or isinstance(key, tuple)
2618 and any(isinstance(x, dict) for x in key)
2619 ):
2620 raise TypeError(
2621 "Passing a dict as an indexer is not supported. Use a list instead."
2622 )
TypeError: Passing a set as an indexer is not supported. Use a list instead.
time: 2.13 s (started: 2023-05-24 14:28:32 +00:00)
3) Visualize cell cycle phases#
By default the cell cycle phase information in stored under cell attribute table under column/key RNA_cell_cycle_phase.
We can color the UMAP plot based on these values.
ds.plot_layout(
layout_key='RNA_UMAP',
color_by='RNA_cell_cycle_phase',
cmap='tab20',
)

time: 487 ms (started: 2023-05-24 14:28:34 +00:00)
We can clearly see that cycling group of cells in the ‘ductal’ group. You can provide your own custom color mappings like below:
color_key = {
'G1': 'grey',
'S': 'orange',
'G2M': 'crimson',
}
ds.plot_layout(
layout_key='RNA_UMAP',
color_by='RNA_cell_cycle_phase',
color_key=color_key,
)
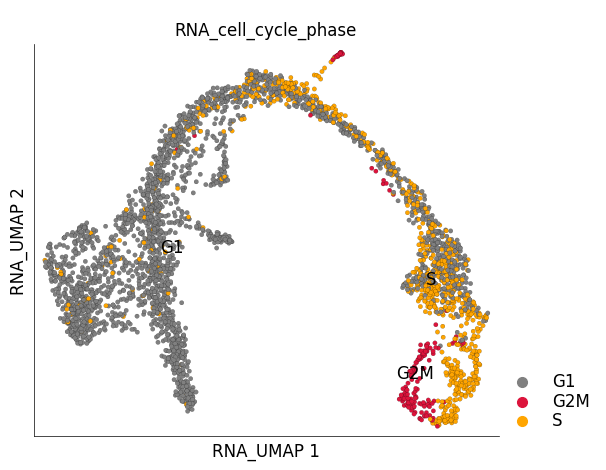
time: 489 ms (started: 2023-05-24 14:28:35 +00:00)
4) Visualize phase specific scores#
The individual and S and G2M scores for each cell are stored under columns RNA_S_score and RNA_G2M_score. We can visualize the distribution of these scores on the UMAP plots
ds.plot_layout(
layout_key='RNA_UMAP',
color_by=['RNA_S_score', 'RNA_G2M_score'],
width=4.5, height=4.5,
)
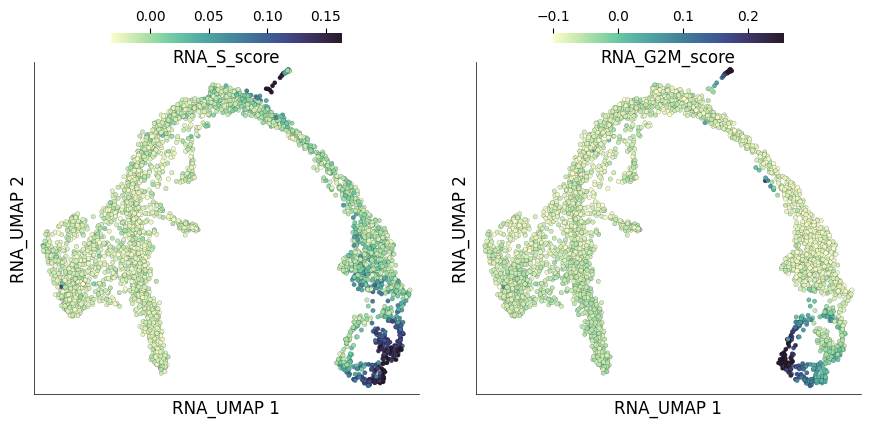
time: 2.14 s (started: 2023-05-24 14:28:35 +00:00)
5) Compare with scores calculated using Scanpy#
The dataset we downloaded, already had cell cycle scores calculated using Scanpy. For example, the S phase scores are stored under the column S_score. We can plot these scores on the UMAP.
ds.plot_layout(
layout_key='RNA_UMAP',
color_by='S_score',
)
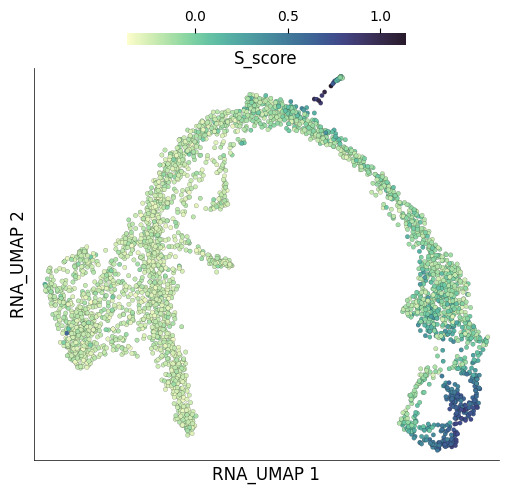
time: 990 ms (started: 2023-05-24 14:28:37 +00:00)
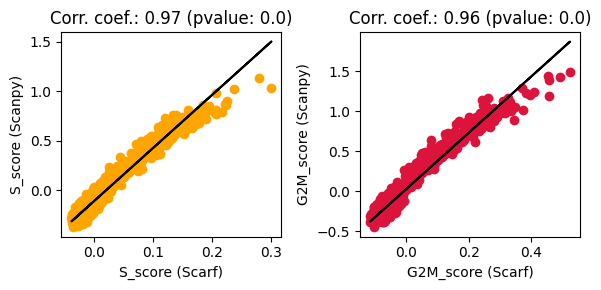
Unsurprisingly, these scores look very similar to those obtained through Scarf. Let’s quantify the concordance below
import matplotlib.pyplot as plt
from scipy.stats import linregress
fig, axis = plt.subplots(1, 2, figsize=(6,3))
for n,i in enumerate(['S_score', 'G2M_score']):
x = ds.cells.fetch(f"RNA_{i}")
y = ds.cells.fetch(i)
res = linregress(x, y)
ax = axis[n]
ax.scatter(x, y, color=color_key[i.split('_')[0]])
ax.plot(x, res.intercept + res.slope*x, label='fitted line', c='k')
ax.set_xlabel(f"{i} (Scarf)")
ax.set_ylabel(f"{i} (Scanpy)")
ax.set_title(f"Corr. coef.: {round(res.rvalue, 2)} (pvalue: {res.pvalue})")
plt.tight_layout()
plt.show()
time: 912 ms (started: 2023-05-24 14:28:38 +00:00)
High correlation coefficients indicate a large degree of concordance between the scores obtained using Scanpy and Scarf
That is all for this vignette.