Merging datasets and partial training¶
This vignette demonstrates how to merge datasets, which are present in different zarr files. The vignette will also demonstrate the steps for performing partial training. Partial PCA training is a lightweight alternative to perform batch effect correction, that often helps obtain a well-integrated embedding and clustering.
[1]:
%config InlineBackend.figure_format = 'retina'
%load_ext autotime
import scarf
scarf.__version__
[1]:
'0.10.1'
time: 986 ms (started: 2021-08-22 19:00:30 +00:00)
1) Fetch datasets in Zarr format¶
Here we will use the same datasets are we use in the ‘data projection’ vignette. We download the files in zarr format.
[2]:
scarf.fetch_dataset('kang_15K_pbmc_rnaseq', save_path='scarf_datasets', as_zarr=True)
scarf.fetch_dataset('kang_14K_ifnb-pbmc_rnaseq', save_path='scarf_datasets', as_zarr=True)
INFO: Download finished! File saved here: /home/docs/checkouts/readthedocs.org/user_builds/scarf/checkouts/0.10.1/docs/source/vignettes/scarf_datasets/kang_15K_pbmc_rnaseq/data.zarr.tar.gz
INFO: Extracting Zarr file for kang_15K_pbmc_rnaseq
INFO: Download finished! File saved here: /home/docs/checkouts/readthedocs.org/user_builds/scarf/checkouts/0.10.1/docs/source/vignettes/scarf_datasets/kang_14K_ifnb-pbmc_rnaseq/data.zarr.tar.gz
INFO: Extracting Zarr file for kang_14K_ifnb-pbmc_rnaseq
time: 25.2 s (started: 2021-08-22 19:00:31 +00:00)
The Zarr files need to be loaded as a DataStore before they can be merged:
[3]:
ds_ctrl = scarf.DataStore('scarf_datasets/kang_15K_pbmc_rnaseq/data.zarr', nthreads=4)
ds_ctrl
[3]:
DataStore has 8487 (14619) cells with 1 assays: RNA
Cell metadata:
'I', 'ids', 'names', 'RNA_UMAP1', 'RNA_UMAP2',
'RNA_leiden_cluster', 'RNA_nCounts', 'RNA_nFeatures', 'RNA_percentMito', 'RNA_percentRibo',
'RNA_unified_UMAP1', 'RNA_unified_UMAP2', 'cluster_labels'
RNA assay has 11352 (35635) features and following metadata:
'I', 'ids', 'names', 'I__hvgs', 'dropOuts',
'nCells'
Projected samples:
'stim'
Co-embeddings:
'unified_UMAP'
time: 19.7 ms (started: 2021-08-22 19:00:56 +00:00)
[4]:
ds_stim = scarf.DataStore('scarf_datasets/kang_14K_ifnb-pbmc_rnaseq/data.zarr', nthreads=4)
ds_stim
[4]:
DataStore has 10111 (14446) cells with 1 assays: RNA
Cell metadata:
'I', 'ids', 'names', 'RNA_UMAP1', 'RNA_UMAP2',
'RNA_leiden_cluster', 'RNA_nCounts', 'RNA_nFeatures', 'RNA_percentMito', 'RNA_percentRibo',
'cluster_labels', 'transferred_labels'
RNA assay has 11051 (35635) features and following metadata:
'I', 'ids', 'names', 'I__hvgs', 'dropOuts',
'nCells'
time: 17.5 ms (started: 2021-08-22 19:00:56 +00:00)
2) Merging datasets¶
The merging step will make sure that the features are in the same order as in the merged file. The merged data will be dumped into a new Zarr file. ZarrMerge class allows merging multiple samples at the same time. Though only one kind of assays can be added at a time, other modalities for the same cells can be added at a later point.
[5]:
#Can be used to merge multiple assays
scarf.ZarrMerge(zarr_path='scarf_datasets/kang_merged_pbmc_rnaseq.zarr', # Path where merged Zarr files will be saved
assays=[ds_ctrl.RNA, ds_stim.RNA], # assays to be merged
names=['ctrl', 'stim'], # these names will be preprended to the cell ids with '__' delimiter
merge_assay_name='RNA', overwrite=True).dump() # Name of the merged assay. `overwrite` will remove an existing Zarr file.
time: 21.6 s (started: 2021-08-22 19:00:56 +00:00)
Load the merged Zarr file as a DataStore:
[6]:
ds = scarf.DataStore('scarf_datasets/kang_merged_pbmc_rnaseq.zarr', nthreads=4)
WARNING: Minimum cell count (562) is lower than size factor multiplier (1000)
time: 16.1 s (started: 2021-08-22 19:01:18 +00:00)
So now we print the merged datastore. The merging removed all the precalculated data. Even the information on which cells were filtered out is lost in the process. This is done deliberately, to allow users to start fresh with the merged dataset.
[7]:
ds
[7]:
DataStore has 29065 (29065) cells with 1 assays: RNA
Cell metadata:
'I', 'ids', 'names', 'RNA_nCounts', 'RNA_nFeatures',
'RNA_percentMito', 'RNA_percentRibo', 'orig_RNA_UMAP1', 'orig_RNA_UMAP2', 'orig_RNA_leiden_cluster',
'orig_RNA_nCounts', 'orig_RNA_nFeatures', 'orig_RNA_percentMito', 'orig_RNA_percentRibo', 'orig_RNA_unified_UMAP1',
'orig_RNA_unified_UMAP2', 'orig_cluster_labels', 'orig_transferred_labels'
RNA assay has 12450 (35635) features and following metadata:
'I', 'ids', 'names', 'dropOuts', 'nCells',
time: 4.99 ms (started: 2021-08-22 19:01:34 +00:00)
If we have a look at the cell attributes table, we can clearly see the that the sample identity is shown in the ids column, prepended to the barcode.
[8]:
ds.cells.head()
[8]:
| I | ids | names | RNA_nCounts | RNA_nFeatures | RNA_percentMito | RNA_percentRibo | orig_RNA_UMAP1 | orig_RNA_UMAP2 | orig_RNA_leiden_cluster | orig_RNA_nCounts | orig_RNA_nFeatures | orig_RNA_percentMito | orig_RNA_percentRibo | orig_RNA_unified_UMAP1 | orig_RNA_unified_UMAP2 | orig_cluster_labels | orig_transferred_labels | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | True | ctrl__AAACATACAATGCC-1 | AAACATACAATGCC-1 | 2191.0 | 852.0 | 0.273848 | 32.131447 | 2.224133 | -7.265071 | 2 | 2191.0 | 852.0 | 0.273848 | 32.131447 | 2.669009 | -7.516445 | CD4 naive T | nan |
| 1 | True | ctrl__AAACATACATTTCC-1 | AAACATACATTTCC-1 | 3018.0 | 878.0 | 0.099404 | 15.440689 | -2.979369 | 14.908970 | 10 | 3018.0 | 878.0 | 0.099404 | 15.440689 | -2.833214 | 13.966822 | CD 14 Mono | nan |
| 2 | True | ctrl__AAACATACCAGAAA-1 | AAACATACCAGAAA-1 | 2481.0 | 713.0 | 0.241838 | 4.957678 | 4.714710 | 9.148883 | 4 | 2481.0 | 713.0 | 0.241838 | 4.957678 | 7.227715 | 10.572861 | CD 14 Mono | nan |
| 3 | True | ctrl__AAACATACCAGCTA-1 | AAACATACCAGCTA-1 | 3157.0 | 950.0 | 0.031676 | 11.308204 | 3.747393 | 13.955492 | 4 | 3157.0 | 950.0 | 0.031676 | 11.308204 | 4.494255 | 13.256012 | CD 14 Mono | nan |
| 4 | True | ctrl__AAACATACCATGCA-1 | AAACATACCATGCA-1 | 703.0 | 337.0 | 0.426743 | 10.953058 | NaN | NaN | -1 | 703.0 | 337.0 | 0.426743 | 10.953058 | NaN | NaN | nan | nan |
time: 40.4 ms (started: 2021-08-22 19:01:34 +00:00)
It can be a good idea to keep track of the cells from different samples, we can fetch out the dataset id from cell-barcodes and add them separately in a new column (this step might get automated in the future).
[9]:
ds.cells.insert(
column_name='sample_id',
values=[x.split('__')[0] for x in ds.cells.fetch_all('ids')],
overwrite=True
)
WARNING: 'values' parameter is of `list` type and not `np.ndarray` as expected. The correct dtype may not be assigned to the column
time: 28.1 ms (started: 2021-08-22 19:01:34 +00:00)
Rather than performing a fresh round of annotation, we will also import the cluster labels from the unmerged datasets. This help us at later steps to evaluate our results.
[10]:
ctrl_labels = list(ds_ctrl.cells.fetch_all('cluster_labels'))
stim_labels = list(ds_stim.cells.fetch_all('cluster_labels'))
ds.cells.insert(
column_name='imported_labels',
values=ctrl_labels + stim_labels,
overwrite=True
)
WARNING: 'values' parameter is of `list` type and not `np.ndarray` as expected. The correct dtype may not be assigned to the column
time: 25.4 ms (started: 2021-08-22 19:01:34 +00:00)
As well as re-using annotations, we import the information about which cells where kept and which ones where filtered out.
[11]:
ctrl_valid_cells = list(ds_ctrl.cells.fetch_all('I'))
stim_valid_cells = list(ds_stim.cells.fetch_all('I'))
ds.cells.update_key(
values=ctrl_valid_cells + stim_valid_cells,
key='I'
)
time: 6.45 ms (started: 2021-08-22 19:01:34 +00:00)
Now we can check the number of cells from each of the samples:
[12]:
ds.cells.to_pandas_dataframe(['sample_id'], key='I')['sample_id'].value_counts()
[12]:
stim 10111
ctrl 8487
Name: sample_id, dtype: int64
time: 13 ms (started: 2021-08-22 19:01:34 +00:00)
3) Naive analysis of merged datasets¶
By naive, we mean that we make no attempt to remove/account for the latent factors that might contribute to batch effect or treatment-specific effect. It is usually a good idea to perform a ‘naive’ pipeline to get an idea about the degree of batch effects.
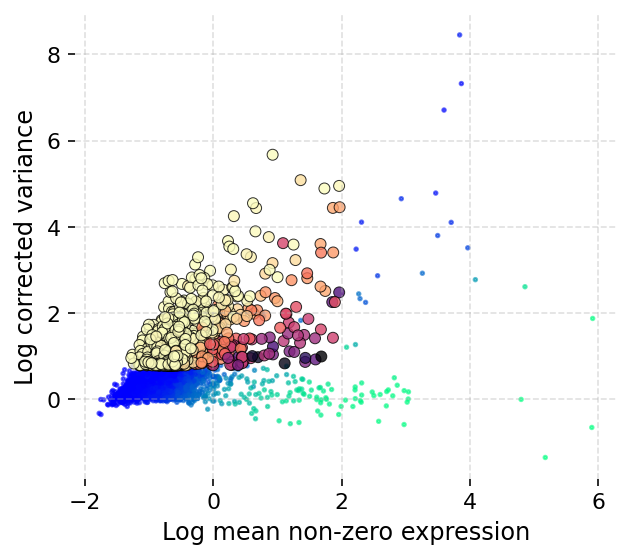
We start with detecting the highly variable genes:
[13]:
ds.mark_hvgs(min_cells=10, top_n=2000, min_mean=-3, max_mean=2, max_var=6)
INFO: 2000 genes marked as HVGs
time: 15 s (started: 2021-08-22 19:01:34 +00:00)
Next, we create a graph of cells in a standard way.
[14]:
ds.make_graph(feat_key='hvgs', k=21, dims=25, n_centroids=100)
INFO: ANN recall: 99.80%
time: 57.8 s (started: 2021-08-22 19:01:49 +00:00)
Calculating UMAP embedding of cells:
[15]:
ds.run_umap(fit_n_epochs=250, spread=5, min_dist=1, parallel=True)
/home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/0.10.1/lib/python3.8/site-packages/umap/umap_.py:1330: RuntimeWarning: divide by zero encountered in power
return 1.0 / (1.0 + a * x ** (2 * b))
completed 0 / 250 epochs
completed 25 / 250 epochs
completed 50 / 250 epochs
completed 75 / 250 epochs
completed 100 / 250 epochs
completed 125 / 250 epochs
completed 150 / 250 epochs
completed 175 / 250 epochs
completed 200 / 250 epochs
completed 225 / 250 epochs
completed 0 / 100 epochs
completed 10 / 100 epochs
completed 20 / 100 epochs
completed 30 / 100 epochs
completed 40 / 100 epochs
completed 50 / 100 epochs
completed 60 / 100 epochs
completed 70 / 100 epochs
completed 80 / 100 epochs
completed 90 / 100 epochs
time: 40.1 s (started: 2021-08-22 19:02:47 +00:00)
[16]:
ds.cells.head()
[16]:
| I | ids | names | RNA_UMAP1 | RNA_UMAP2 | RNA_nCounts | RNA_nFeatures | RNA_percentMito | RNA_percentRibo | imported_labels | ... | orig_RNA_leiden_cluster | orig_RNA_nCounts | orig_RNA_nFeatures | orig_RNA_percentMito | orig_RNA_percentRibo | orig_RNA_unified_UMAP1 | orig_RNA_unified_UMAP2 | orig_cluster_labels | orig_transferred_labels | sample_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | True | ctrl__AAACATACAATGCC-1 | AAACATACAATGCC-1 | -12.234281 | 23.911160 | 2191.0 | 852.0 | 0.273848 | 32.131447 | CD4 naive T | ... | 2 | 2191.0 | 852.0 | 0.273848 | 32.131447 | 2.669009 | -7.516445 | CD4 naive T | nan | ctrl |
| 1 | True | ctrl__AAACATACATTTCC-1 | AAACATACATTTCC-1 | 20.958632 | -23.957098 | 3018.0 | 878.0 | 0.099404 | 15.440689 | CD 14 Mono | ... | 10 | 3018.0 | 878.0 | 0.099404 | 15.440689 | -2.833214 | 13.966822 | CD 14 Mono | nan | ctrl |
| 2 | True | ctrl__AAACATACCAGAAA-1 | AAACATACCAGAAA-1 | 30.767984 | -18.843168 | 2481.0 | 713.0 | 0.241838 | 4.957678 | CD 14 Mono | ... | 4 | 2481.0 | 713.0 | 0.241838 | 4.957678 | 7.227715 | 10.572861 | CD 14 Mono | nan | ctrl |
| 3 | True | ctrl__AAACATACCAGCTA-1 | AAACATACCAGCTA-1 | 27.042004 | -18.111193 | 3157.0 | 950.0 | 0.031676 | 11.308204 | CD 14 Mono | ... | 4 | 3157.0 | 950.0 | 0.031676 | 11.308204 | 4.494255 | 13.256012 | CD 14 Mono | nan | ctrl |
| 4 | False | ctrl__AAACATACCATGCA-1 | AAACATACCATGCA-1 | NaN | NaN | 703.0 | 337.0 | 0.426743 | 10.953058 | nan | ... | -1 | 703.0 | 337.0 | 0.426743 | 10.953058 | NaN | NaN | nan | nan | ctrl |
5 rows × 22 columns
time: 48.2 ms (started: 2021-08-22 19:03:27 +00:00)
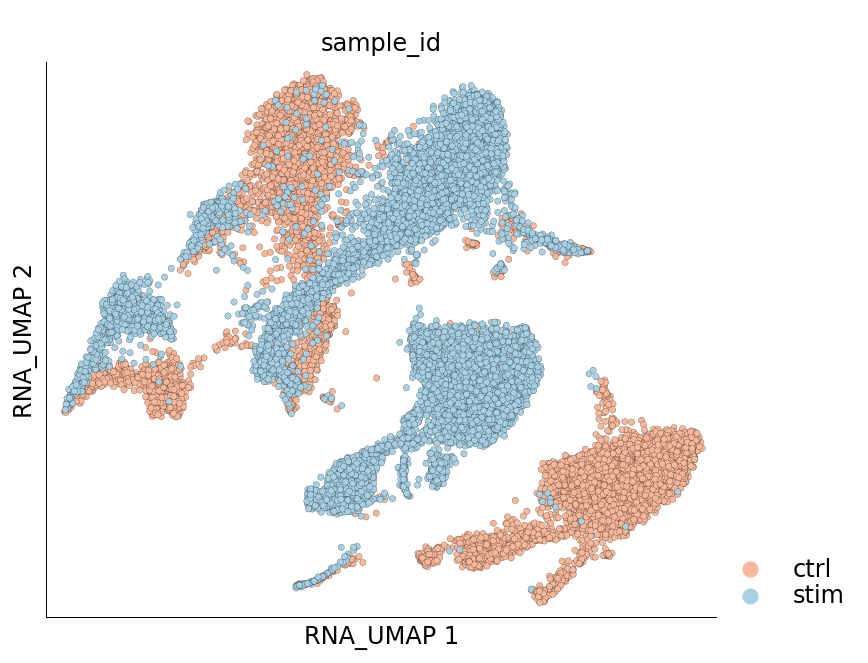
Visualization of cells from the two samples in the 2D UMAP space:
[17]:
ds.plot_layout(layout_key='RNA_UMAP', color_by='sample_id', cmap='RdBu', legend_ondata=False)
time: 627 ms (started: 2021-08-22 19:03:27 +00:00)
Visualization of cluster labels in the 2D UMAP space:
[18]:
ds.plot_layout(layout_key='RNA_UMAP', color_by='imported_labels', legend_ondata=False)
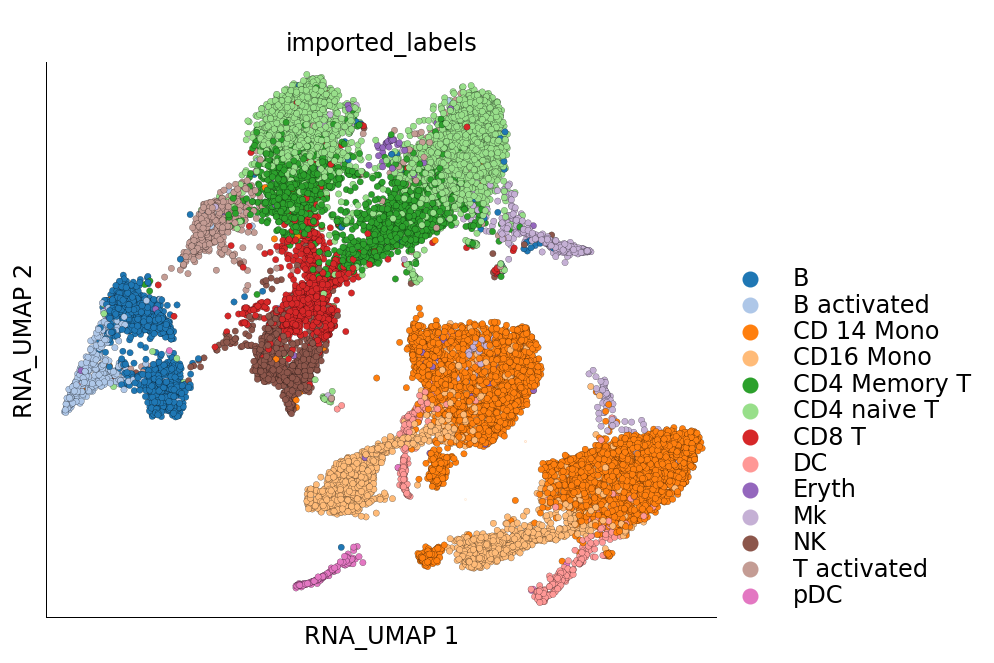
time: 965 ms (started: 2021-08-22 19:03:28 +00:00)
4) Partial PCA training to reduce batch effects¶
The plots above clearly show that the cells from the two samples are distinct on the UMAP space and have not integrated. This clearly indicates a treatment-specific or simply a batch effect between the cells from the two samples. Another interesting pattern in the UMAP plot above is the ‘mirror effect’, i.e. the equivalent clusters from the two samples look like mirror images. This is often seen in the datasets where the heterogenity/cell population composition is not strongly affected by the treatment.
We will now attempt to integrate the cells from the two samples so that we obtain same cell types that do not form separate clusters. One can do this by training the PCA on cells from only one of the samples. Training PCA on cells from only one of the samples will diminish the contribution of genes differentially expressed between the two samples.
First, we need to create a boolean column in the cell attribute table. This column will indicate whether a cell belongs to one of the samples. Here we will create a new column is_ctrl and mark the values as True when a cell belongs to the ctrl sample.
[19]:
ds.cells.insert(column_name=f'is_ctrl',
values=(ds.cells.fetch_all('sample_id') == 'ctrl'),
overwrite=True)
time: 3.61 ms (started: 2021-08-22 19:03:29 +00:00)
The next step is to perform the partial PCA training. PCA is trained during the graph creation step. We will now use pca_cell_key parameter and set it to is_ctrl so that only ‘ctrl’ cells are used for PCA training.
[20]:
ds.make_graph(feat_key='hvgs', k=21, dims=25, n_centroids=100, pca_cell_key='is_ctrl')
INFO: Using existing normalized data with cell key I and feat key I__hvgs
INFO: ANN recall: 99.77%
time: 28.8 s (started: 2021-08-22 19:03:29 +00:00)
We run UMAP as usual, but the UMAP embeddings are saved in a new cell attribute column so as to not overwrite the previous UMAP values. The new column will be called RNA_pUMAP; ‘RNA’ is automatically prepend because the assay name is RNA
[21]:
ds.run_umap(fit_n_epochs=250, spread=5, min_dist=1, parallel=True, label='pUMAP')
/home/docs/checkouts/readthedocs.org/user_builds/scarf/envs/0.10.1/lib/python3.8/site-packages/umap/umap_.py:1330: RuntimeWarning: divide by zero encountered in power
return 1.0 / (1.0 + a * x ** (2 * b))
completed 0 / 250 epochs
completed 25 / 250 epochs
completed 50 / 250 epochs
completed 75 / 250 epochs
completed 100 / 250 epochs
completed 125 / 250 epochs
completed 150 / 250 epochs
completed 175 / 250 epochs
completed 200 / 250 epochs
completed 225 / 250 epochs
completed 0 / 100 epochs
completed 10 / 100 epochs
completed 20 / 100 epochs
completed 30 / 100 epochs
completed 40 / 100 epochs
completed 50 / 100 epochs
completed 60 / 100 epochs
completed 70 / 100 epochs
completed 80 / 100 epochs
completed 90 / 100 epochs
time: 40 s (started: 2021-08-22 19:03:58 +00:00)
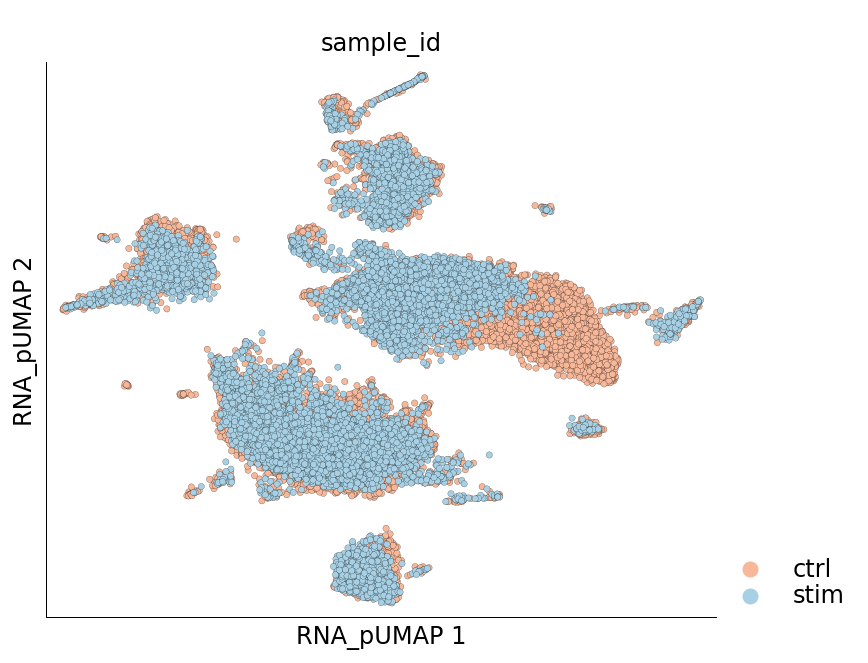
Visualize the new UMAP
[22]:
ds.plot_layout(layout_key='RNA_pUMAP', color_by='sample_id', cmap='RdBu', legend_ondata=False)
time: 620 ms (started: 2021-08-22 19:04:38 +00:00)
Visualization of cluster labels in the new UMAP space shows that the cells from the same cell-type do not split into separate clusters like they did before.
[23]:
ds.plot_layout(layout_key='RNA_pUMAP', color_by='imported_labels', legend_ondata=False)

time: 818 ms (started: 2021-08-22 19:04:38 +00:00)
That is all for this vignette.